



In actuality, not every firm may be a good fit for the implementation of a Data Mesh. Larger enterprises that experience uncertainty and change in their operations and environment are the primary target audience for Data Mesh.
A Data Mesh is definitely an unnecessary expense if your organization's data requirements are modest and remain constant over time.
What is a "Data Mesh"?

As it focuses on delivering useful and safe data products, Data Mesh is a strategic approach to modern data management and a strategy to support an organization's journey toward digital transformation. Data Mesh's major goal is to advance beyond the established centralized data management techniques of using data warehouses and data lakes. By giving data producers and data consumers the ability to access and handle data without having to go through the hassle of involving the data lake or data warehouse team, Data Mesh highlights the concept of organizational agility. Data Mesh's decentralized approach distributes data ownership to industry-specific organizations that use, control, and manage data as a product. From Wikipedia, the definition of Data Mesh:
"Data mesh is a socio-technical approach to build a decentralized data architecture by leveraging a domain-oriented, self-serve design (in a software development perspective), and borrows Eric Evans’ theory of domain-driven design and Manuel Pais’ and Matthew Skelton’s theory of team topologies. Data mesh mainly concerns about the data itself, taking the Data Lake and the pipelines as a secondary concern. The main proposition is scaling analytical data by domain-oriented decentralization. With data mesh, the responsibility for analytical data is shifted from the central data team to the domain teams, supported by a data platform team that provides a domain-agnostic data platform."
The four underlying ideas of the Data Mesh concept are as follows:
- Data as a Product
- Domain focussed ownership
- Self-Service Infrastructure for Data
- Federated Governance on Computational Level
Let's examine the four principles in more detail.
Data as a Product
In order to provide commercial value, data products are created by the domain and consumed by users or downstream domains. Data products are distinct from conventional data marts in that they are self-contained and in charge of all infrastructure, security, and provenance issues connected to maintaining the data's accuracy. Data products enhance business intelligence and machine learning efforts by enabling a clear line of ownership and responsibility. They can be used by other data products or by end users directly.
Domain focussed ownership
We must first understand what a domain is in order to comprehend domain-driven data. A domain is a group of people gathered for a common practical business goal. According to Data Mesh, the domain should be in charge of managing the data that is related to and generated by its business function. The assimilation, transformation, and delivery of data to end users are the domains' responsibilities. The domain eventually makes its data available as data products, which it has the rights to during their full existence.
Self-Service Infrastructure for Data
In order for members of the domains to easily develop and maintain their data products, a self-serve data infrastructure must consist of a wide range of capabilities. The infrastructure engineering team that supports the self-serve data platform is primarily focused on managing and running the numerous technologies in use. This demonstrates how domains are concerned with data, while the team working on the self-serve data platform is concerned with technology. The independence of the domains serves as a barometer for the self-serve data platform's performance.
Federated Governance at the Computational Level
It is possible to view conventional data governance as a barrier to generating value from data. By integrating governance issues into the workflow of the domains, Data Mesh makes it possible to take a new approach. Although there are many facets to data governance, it is crucial that usage metrics and reporting are included when talking about Data Mesh. The number and type of data usage are crucial data points for determining the worth and, consequently, the success, of specific data products.
Business reasons and advantages of a Data Mesh
Data Mesh deployment encourages organizational agility for businesses that want to prosper in a volatile economic environment. Every firm must be able to react to environmental changes with a low-cost, high-reward strategy. Changes in regulatory requirements, the need to comply with new analytics requirements, and the introduction of new data sources are all factors that will cause an organization's data management processes to alter. In light of these dynamics, current approaches to data management are frequently built on intricate and tightly connected ETL between operational and analytical systems that struggle to adapt in time to meet business objectives. The goal of Data Mesh is to offer a more adaptable approach to data so that it can effectively react to such changes.
Deep Technology: Required to set up and run a Data Mesh
Technology capabilities are a crucial facilitator for putting a Data Mesh into operation. For a number of reasons, new technology is probably necessary.
- The interoperability of those new technologies is going to be crucial in lowering the friction associated with technology exploitation.
- Allow domains to function independently and concentrate on data, which is their primary priority, rather than technology.
- Enabling the purchase of new data platforms online and the seamless exploitation of the data they disclose.
- Enable automatic reporting of governance elements throughout the data mesh, including data product usage, standard compliance, and customer feedback.
Participants: Decentralized domains to a central data team
A Data Mesh journey will involve significant organizational changes and modifications to the responsibilities of the people. Existing employees will be essential to the adoption of a Data Mesh's success because they can offer the Data Mesh's journey rich tacit knowledge. Therefore, a realignment of current data-focused staff as well as the transfer of data ownership from a central data team to decentralized domains should be considered. In addition, reward systems and managerial structures have changed.
Process optimization: Internal organizational changes
By implementing a Data Mesh, the business will need to make adjustments to its internal processes in order to encourage a resilient and flexible data architecture. If we take data governance into account, new processes for defining, implementing, and enforcing data policies will be needed. These processes will have an impact on how data is accessed, managed, and used in established daily activities and well-known processes. Additionally, a well-designed Data Mesh enables process mining over the whole data lifecycle chain to enable much more efficient process management and design.
Data Lakes, Data Fabrics and Data Mesh - what is what?
The data lake is a technology approach whose primary goal has traditionally been to serve as a single repository to which data can be moved as easily as possible, with the central team in charge of managing it. While data lakes can provide significant business value, they are not without flaws. The main issue is that once data is moved to the lake, it loses context. For example, we may have several files containing a customer definition, one from a logistics system, one from payments, and one from marketing; which one is correct for my use? Furthermore, because the data in the data lake has not been pre-processed, data issues will inevitably arise. This creates a significant barrier to using the data to address the original business question because the data consumer will typically need to communicate with the data lake team to comprehend and resolve data issues.
A data mesh, on the other hand, is more than just technology; it combines both technology and organizational aspects, such as the concepts of data ownership, data quality, and autonomy. As a result, data consumers have a clear line of sight regarding data quality and ownership, and data issues can be discovered and resolved much more efficiently. Data can eventually be used and trusted.
A data fabric focuses on a collection of multiple technology capabilities that work together to create an interface for data consumers. Various advocates of data fabric advocate for the automation of many data management chores with technologies such as ML to allow end users to access data more easily. There is some utility in this for simple data utilization, but for more complicated circumstances or when business knowledge has to be integrated into the data, the limits of Data Fabric will become obvious.
It is to add that a data fabric might perhaps be utilized as part of a Data Mesh self-serve platform, exposing data to domains who can then insert their business expertise into the final data product.
Blossom Sky creates an AI-focused data mesh for your data infrastructure
Organizations that are ready to adopt Data Mesh will want assistance in connecting their data sources in order to achieve a rapid win with Databloom’s Next-Gen Data Mesh. Basically, those two steps need to be taken to bring your enterprise to the next level of future-proven data management:
Connect to the data sources where it is stored
The first step in starting your Data Mesh journey is to connect to data sources. A fundamental Data Mesh implementation idea is to connect your data sources by using your existing investments: data lakes or data warehouses; cloud or on-premise; structured warehouses or unstructured lakehouses. In contrast to the single-source-of-truth method of initially centralizing all your data, you are using and querying the data where it sits. It is many of our clients’ first Data Mesh win, since our open core and attachable connectors enable our customers to connect to data sources like SQL, text, Big Data or Tensorflow.
Make it possible for teams to create data products
After providing a data team with the data they want, the next step is to teach them how to turn data sets into data products. Then, using a data product, establish a data product library or catalog. Blossom Studio includes a catalog that allows you to swiftly search for, find, and identify data items that may be of interest.
Because you are swiftly producing and then deploying data products across the enterprise, creating data products is a strong competency because you've enabled your data consumers to quickly move from discovery to ideation and insight.
Building and maintaining a Data Mesh
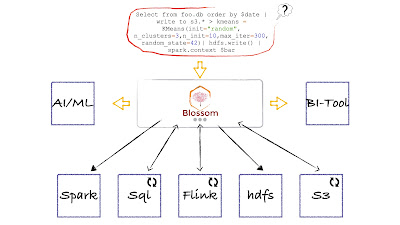
The Blossom Development Environment (BDE) or Apache Wayang will be useful for those who are eager to begin or are just beginning their Data Mesh adventure. In fact, many book a Solution Architect with us to assist them in completing this challenging and rewarding task. It does not bind too much labor and may be low cost, low risk, and have a great payoff with the appropriate plan. The exercise to determine how Data Mesh will fit into your business from a technology, people, and process standpoint is the goal of a session with our Solution Architects. You’ll also be able to assess your strengths and limitations, which will help you, when you’re ready to start your Data Mesh transformation program, curate all the learnings to speed up where you can move swiftly and slack off where you need remedial work. A session with a specialized architect from us consists of a three-hour consultation in which we discuss:
- The scope and choose the use case.
- Which Pre-MVP environments must be established for early design and enabling efforts.
- How to design, improve, and use data products.
- And finally embrace the Data Mesh as a part of your data strategy.
Book a consultation with us over our contact form, we are here to help you in your journey to a future ready data driven organization.
About Scalytics
We enable you to make data-driven decisions in minutes, not days
Scalytics is powered by Apache Wayang, and we're proud to support the project. You can check out their public GitHub repo right here. If you're enjoying our software, show your love and support - a star ⭐ would mean a lot!
If you need professional support from our team of industry leading experts, you can always reach out to us via Slack or Email.







